3장 고객의 전체 모습을 파악하는 테크닉 10
intro
데이터 분석의 목적 : 현재의 데이터를 통해 미래를 예측하는 것이다. 이는 현황을 분석하여 문제점을 파악하고 더 좋은 미래로 바꾸기 위해 최적의 정책을 실시할 수 있게 하는 것이다.
데이터 가공의 필요성
- 적절한 가공과 가시화만으로도 많은 정보를 얻을 수 있다.
3장에서 배울 내용
- 머신러닝을 위한 데이터 가공 기술을 배우면서 고객 행동을 분석하고 파악하는 노하우
문제 상황
최근 1년간 고객 수가 늘지 않는 문제이다. 기존의 고객과 특성과 이용하는 빈도가 낮은 고객에 대한 정보도 알고 싶다.
전제 조건
고객의 종류
- 1. 종일 회원
- 낮에만 이용하는 주간 회원
- 야간회원
- 비정기 회원, 입회비에선 행사로 들어온 회원
취급할 데이터
| No. | 파일 이름 | 개요 |
| 1 | use_log.csv | 센터 이용 이력 / 2018년 4월 ~ 2019년 3월까지 약 1년간의 데이터 |
| 2 | customer_master.csv | 2019년 3월 말 시점 시점의 회원 데이터 |
| 3 | class_master.csv | 회원 구분 |
| 4 | campaign_master.csv | 가입 시 행사 구분 데이터 |
테크닉 21. 데이터를 읽어 들이고 확인하자
import pandas as pd
uselog = pd.read_csv('use_log.csv')
print(len(uselog))
uselog.head()
customer = pd.read_csv('customer_master.csv')
print(len(customer))
customer.head()
class_master = pd.read_csv('class_master.csv')
print(len(class_master))
class_master.head()
campaign_master = pd.read_csv('campaign_master.csv')
print(len(campaign_master))
campaign_master.head()



head()를 통해 처음 5행의 정보를 알 수 있다.
use_log.csv : 고객 id, 이용일이 포함됨
customer_master.csv : id, 이름, 회원 클래스, 성별, 등록일 정보, is_deleted 열은 탈퇴한 유저를 찾기 위한 열이다.
class_master.csv : id, 회원 구분
campaign_master.csv : id, 캠페인 구분 데이터
이번 장에서 이용할 데이터는 "use_log", "customer" 데이터이다.
테크닉22. 고객 데이터를 가공하자
데이터 가공에서 customer에 회원 구분 class_master와 캠페인 구분 campaign_master를 결합하여 customer_join을 새로 생성한다. 고객 데이터를 중심으로 가로로 결합하는 레프트 조인이다.
customer_join = pd.merge(customer, class_master, on="class",how ="left"_
customer_join = pd.merge(customer_join, campaign_master, on= "campaign_id", how="left")
customer_join.head()
출력 결과를 보면 각각 class_name, price, campaign_name 칼럼이 추가되어 회원 구분과 금액을 알 수 있게 되었다.
join 시 주의 할 점.
조인이 잘못되면 결측치가 들어가기 때문에 조인 후에는 결측치를 확인해야 한다.
customer_join.isnull().sum()
테크닉23. 고객 데이터를 집계하자
데이터 가공을 완료 후에는 고객 데이터를 집계하여 전체 모습을 살펴보자.
이에 대한 방법에는
1) 각 칼럼에서 무슨 값이 많이 나왔는지?
2) 값에 대한 비율은 어떠한지?
전체 숫자를 파악하는 코드는 아래와 같다.
customer_join.groupby("class_name").count()["customer_id"]
customer_join.groupby("campaign_name").count()["customer_id"]
customer_join.groupby("gender").count()["customer_id"]
customer_join.groupby("is_deleted").count()["customer_id"]코드는 groupby 함수를 사용하여 집계했고, 이번에는 customer_id로 카운트했다.
이 다음에 생기는 여러 가설이나 캠페인이 시행된 시기, 성별과 회원 클래스의 관계, 올해 가입 인원처럼 궁금한 점이 생길 것으로 생각된다.
how to get advanced understanding?
이런 가설이나 의문점은 집계해서 확인하는 것이 아니라, 현장 사람들에게 질문함으로써 이해할 수 있는 것이 많다.
특정 기간의 날짜를 가져오기
start_date가 2018년 4월 1일 이후부터 2019년 3월 31일까지인 가입 인원을 시험삼아 집계해 보자.
1부에서 사용한 것처럼 먼저 이 열을 datetime형으로 변환한 후, customer_start 변수에 해당 유저의 데이터를 저장하고 개수를 세어보자.
customer_join["start_date"] = pd.to_datetime(customer_join["start_date"]
customer_start= customer_join.loc[customer_join["start_date"] > pd.to_datetime("20180401")]
print(len(customer_start))코드를 실행하면 1361이 출력되는데, 이는 이 기간의 가입인원이 1361명인 것을 알 수 있다.
이 코드의 kick은 customer_join["start_date"] > pd.to_datetime("20180401")이 구문이라고 생각한다.
테크닉24. 최신 고객 데이터를 집계하자
가장 최근의 월(2019년 3월)의 고객 데이터를 파악해 보자.
고려해야 할 점.
- 이미 탈회한 고객 정보로 인한 월별 집계와의 차이
최근 월의 고객 데이터만 추출하기
방법
- 2019년 3월에 탈퇴한 고객과 재적 중인 고객을 추출한다.
- is_deleted 열로 추출하는 방법
- 이 방법은 2019년 3월에 탈퇴한 고객은 집계대상에서 제외된다는 점을 유의해야 한다.
<코드>
대상 고객을 추출하자
추출한 데이터가 제대로 추출되었는지 확인하기 위해 end_date의 유니크 개수를 확인해 보자.
customer_join["end_date"] = pd.to_datetime(customer_join["end_date"])
customer_newer = customer_join.loc[(customer_join["end_date"] >= pd.to_datetime("20190331")) | (customer_join["end_date"].isna())]
print(len(customer_newer))
customer_newer["end_date"].unique()출력한 결과, 데이터는 2,952건이고, end_date의 유니크는 NaT로, 2019-03-31만 표시된다면 올바르게 추출된 것이다.
NaT : datetime형의 결측치라는 의미로, 여기서는 탈퇴하지 않은 고객을 나타낸다.
코드에 들어간 함수에 대해 설명하기
customer_join.loc[(customer_join["end_date"] >= pd.to_datetime("20190331")) | (customer_join["end_date"].isna())]
print(len(customer_newer))
회원 구분, 캠페인 구분, 성별로 전체를 파악하기
customer_newer.groupby("class_name").count()["custoemr_id"]
customer_newer.groupby("campaign_name").count()["custoemr_id"]
customer_newer.groupby("gender").count()["custoemr_id"]

위의 출력 결과를 통해 회원이나 성비는 큰차이가 없었지만, 일반 회원의 비율이 크게 증가한 것을 알 수 있기에 캠페인은 회원 비율 변화에 영향을 미친다고 추측할 수 있다.
이제 이용 이력 데이터의 활용을 검토하자.
이용 이력 데이터의 특징
- 시간적인 요소를 분석할 수 있다.
- 한 달 이용 횟수의 변화
- 회원의 정기적/ 비정기적인 것의 유무를 알 수 있다.
테크닉25. 이용 이력 데이터를 집계하자
코드를 통해 간단히 시간적인 요소를 도입해보자.
평균값, 중앙값, 최댓값, 최솟값과 정기적 이용 여부를 플래그로 작성해서 고객 데이터에 추가하자.
고객마다 월 이용 회수를 집계한 데이터를 코드로 구현하자.
uselog["usedate"]= pd.to_datetime(uselog["usedate"])
uselog["연월"] = uselog["usedate"].dt.strftime("%Y%m")
uselog_months = uselog.groupby(["연월", "customer_id"], as_index=False).count()
uselog_months.rename(columns = {"log_id":"count"}, inplace = True)
del uselog_months["usedate"]
uselog_months.head()
1과 2행에선 201804와 같은 형식으로 연월 칼럼의 데이터를 작성하고, 연월과 고객 ID별로 groupby로 집계한다.
집계는 log_id를 카운트하면 되므로 필요 없는 usedate는 삭제한다.
uselog_customer = uselog_months.groupby("customer_id").agg(["mean","median","max","min"])["count"]
uselog_customer = uselog_customer.reset_index(drop=False)
uselog_customer.head()
1행에서 groupby로 평균, 중앙, 최대, 최소를 집계했다.
2행에서는 groupby의 영향으로 customer_id가 index에 들어 있기에 이것을 칼럼으로 변경합니다.
agg함수의 역할
reset_index(drop=False)의 의미
groupby("customer_id").agg(["mean","median","max","min"])["count"] 사용방법
테크닉26. 이용 이력 데이터로부터 정기 이용 플래그를 작성하자
플래그가 무엇이니?
스포츠 센터의 경우에 지속 요소가 습관이 있다.
습관을 판단하는 방법
- 월/요일별로 집계
- 최댓값이 4 이상인 요일이 하나라도 있는 회원을 플래크를 1로 처리
uselog["weekday"] = uselog["usedate"].dt.weekday
uselog_weekday = uselog.groupby(["customer_id","연월", "weekday"],as_index=False).count()[["customer_id","연월","weekday","log_id"]]
uselog_weekday.rename(columns={"log_id":"count"},inplace=True)
uselog_weekday.head()
- 1행 : 요일을 숫자로 변환했다.
- 0~6까지가 월~일이다.
- 2행 : 고객, 연월, 요일별로 log_id를 셉니다.
고객별로 최댓값을 계산하고, 그 최댓값이 4이상인 경우에 플래크를 지정해보자.
uselog_weekday = uselog_weekday.groupby("customer_id", as_index=False).max()[["customer_id", "count"]]
uselog_weekday["routine_flg"] = 0
uselog_weekday["routine_flg"] = uselog_weekday["routine_flg"].where(uselog_weekday["count"]<4,1_
uselog_weekday.head()
1행 : 고객 단위로 집계하고, 해당 고객의 count 열의 값 중에서 최댓값을 구했다.
2행 : routine_flg에 0을 입력하고
3행 : 횟수가 4 미만인 경우는 원래의 값인 0을 그대로, 4 이상인 경우는 1을 대입한다.
테크닉27. 고객 데이터와 이용 이력 데이터를 결합하자
customer_join = pd.merge(customer_join, uselog_customer, on = "customer_id", how="left")
customer_join = pd.merge(custoemr_join, use_log_weekday[["customer_id","routine_flg"]],on="customer_id",how="left")
customer_join.head()customer_join.isnull().sum()
테크닉28. 회원 기간을 계산하자
계산 : start_date 와 end_date의 차이
탈퇴하지 않은 회원의 경우 :
- 2019년 3월까지 탈퇴하지 않은 회원은 end_date에 결측치가 들어 있기 때문에 차이를 계산할 수 없다.
- sol : 2019년 4월 30일로 채워서 회원 기간을 계산한다.
- why? 2019/3/31에 탈퇴한 사람과 구별할 수 없기 때문.
월 단위로 집계
from dateutil.relativedelta import relativedelta
customer_join["calc_date"] = cusomer_join["end_date"]
customer_join["calc_date"] = customer_join["calc_date"].fillna(pd.to_datetime("20190430"))
customer_join["membership_period"] = 0
for i in range(len(customer_join)):
delta = relativedelta(customer_join["calc_date"].iloc[i], customer_join["start_date"].iloc[i])
customer_join["membership_period"].iloc[i] = delta.years*12 + delta.months
customer_join.head()
1행 : 날짜 비교 함수 relativedelta를 사용하기 위해 라이브러리를 임포트
2행 날짜 계산용 칼럼 end_date를 기준으로 작성
3행에서 결측치에 2019년 4월 30일을 대입
for문에선 월 단위로 계산함으로써 회원 기간 칼럼을 추가한다.
테크닉29. 고객 행동의 각종 통계량을 파악하자
customer_join[["mean","median","max","min"]].describe()mean : 매월 평균 이용횟수
customer_join.groupby("routine_flg").count()["customer_id"]1이 많다는 것은 정기적으로 이용하는 고객이 많다.
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(customer_join["membership_period"])
이는 10개월 이내인 고객이 많고, 10개월 이상의 고객 수는 일정한 것을 알 수 있기에, 이는 짧은 기간에 고객이 빠져나가는 업계라는 것을 시사한다.
테크닉30. 탈퇴 회원과 지속 회원의 차이를 파악하자
탈퇴 회원의 특징을 찾아보는 방법
탈퇴와 지속을 나눠서 각각 describe로 비교하는 것이다.
customer_end = customer_join.loc[customer_join["is_labeled"]==1]
customer_end.describe()
customer_stay = customer_join.loc[customer_join["is_deleted"]==0]
customer_stay.describe()
저장하기
customer_join.to_csv("customer_join.csv", index=False)
4장 고객의 행동을 예측하는 테크닉 10
클러스터링의 근거
회원의 행동은 이용 빈도 등에 따라 경향이 크게 달라지기에 군집화를 함으로써 회원을 그룹화하고,
이를 통해 행동 패턴을 파악함으로써 미래 예측의 정확도를 높이는 것이 가능해진다.
| No. | 파일 이름 | 개요 |
| 1 | use_log.csv | 센터 이용 이력 / 2018년 4월 ~ 2019년 3월까지 약 1년간의 데이터 |
| 2 | customer_master.csv | 2019년 3월 말 시점 시점의 회원 데이터 |
| 3 | class_master.csv | 회원 구분 |
| 4 | campaign_master.csv | 가입 시 행사 구분 데이터 |
| 5 | customer_join.csv | 3장에서 작성한 이용 이력을 포함한 고객 데이터 |
테크닉31. 데이터를 읽어 들이고 확인하자.
import pandas as pd
uselog = pd.read_csv('use_log.csv')
uselog.isnull().sum()
customer = pd.read_csv('customer_join.csv')
customer.isnull().sum()
이 코드를 통해 end_date 이외에는 결측치가 0인 것을 확인할 수 있다.
고객 데이터를 그룹화함으로써 탈퇴 여부를 분류하는 것이 아닌, 이용 이력을 이용해서 그룹화해 보자.
이는 비지도학습 클러스터링을 이용할 것이다.
테크닉32. 클러스터링으로 회원을 그룹화하자
customer 데이터를 사용해서 회원 그룹화를 진행한다. 클러스터링에 이용하는 변수는 고객의 한 달 이용 이력 데이터인 mean, median, max, min, membership_period로 5가지이다.
변수 추출 단계
customer_clustering = customer[["mean", "median", "max", "min", "membership_period"]]
customer_clustering.head()customer_clustering에 추출한 데이터를 넣음으로써 새로운 데이터 셋을 만들었다.
이제 클러스터링을 진행하자.
가장 전통적인 방법은 변수간의 거리를 기반으로 그룹화를 진행하는 K-means이다.
고려사항
- 미리 그룹의 개수를 정해야 한다.
- 데이터 간의 최댓값의 차이가 큰 경우에는 값이 큰 것으로 결과가 정해지므로 표준화를 해야 한다.
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
sc= StandardScaler()
customer_clustering_sc = sc.fit_transform(customer_clustering)
kmeans = KMeans(n_clusters=4, random_state =0)
clusters= kmeans.fit(customer_clustering_sc)
customer_clustering["cluster"]=clusters.labels_
print(customer_clustering["cluster"].unique())
customer_clustering.head()
1행 : K-means 임포트
2행 : 표준화를 위해 scikit-learn 임포트
3행과 4행 : 표준화를 실행하고, customer_clustering_sc에 저장
Kmeans 모델을 정의
데이터를 이용한 클러스터링 모델을 구축함.
원래 데이터에 클러스터링 결과를 반영함.
테크닉33. 클러스터링 결과를 분석하자
customer_clustering.columns = ["월평균값", "월중앙값", "월최댓값", "월최솟값", "회원기간", "cluster"]
customer_clustering.groupby("cluster").count()이는 cluster의 값을 기준으로 object의 개수를 세고 있는 것이다.

그룹의 특징을 파악하기 위해 그룹마다 평균값을 계산해 봅시다.
customer_clustering.groupby("cluster").mean()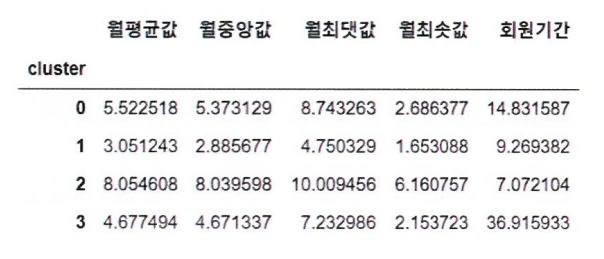
출력 결과를 통해 그룹 2는 회원 기간이 짧지만, 이용률이 높은 회원이라는 것을 알 수 있다.
그룹 3은 회원 기간은 길지만, 이용률이 약간 낮은 것을 알 수 있다.
테크닉34. 클러스터링 결과 가시화
사용한 변수가 5개이지만, 이를 2차원으로 그리기 위해 차원을 축소해야 한다.
차원 축소 :
- 비지도학습의 일종으로, 정보를 잃지 않게 하면서 새로운 축을 만드는 것이다. 이를 통해 표현하는 변수를 줄임으로써 그래프로 그릴 수 있게 된다.
- 방법 : 주성분 분석
from sklearn.decomposition import PCA
X =