10장 앙케트 분석을 위한 자연어 처리 테크닉 10
91. 데이터 불러서 파악해 보자
import pandas as pd
survey = pd.read_csv("survey.csv")
print(len(survey))
survey.head()

이처럼 코드를 실행하면 datetime, comment(의견), satisfaction(만족도)를 확인할 수 있다.
결측치 확인
survey.isna().sum()
아래의 결과가 결측치이다.
그래서 설문조사의 경우는 결측치가 많은 경우가 있기에 반드시 결측치를 확인해야 한다.
86개중 2가지가 결측치인 경우는 제거해준다.
survey = survey.dropna()
survey.isna().sum()
제거가 완료된 것을 볼 수 있다.
92. 불필요한 문자를 제거하자.
언어는 사람에 따라 쓰는 방법이 다르고, 공백 및 괄호를 붙이거나 붙이지 않거나 하는 등의 여러 가지 형태가 있다.
그래서 괄호를 비롯한 불필요한 문자를 제거하는 귀찮은 작업이 이어진다.
여기선 AA를 제거해보자.
survey["comment"] = survey["comment"].str.replace("AA", "")
survey.head()
replace함수를 사용하면 특정 문자열을 치환할 수 있다.
위에는 (역), (대기아동 없음)과 같이 괄호 안에 단어가 있는 형태가 있다. 이런 괄호와 괄호 안의 내용을 제거하려면 어떻게 해야 할까? 문자를 일정한 규칙으로 제거할 때는 정규표현식을 사용하는 것이 좋다.
정규표현식은 문자 등의 패턴을 표현할 수 있으며, 정규표현식 사용을 통해 괄호의 패턴을 검색해서 치환할 수 있다.
survey["comment"] = survey["comment"].str.replace("\(.+?\)", "")
survey.head()
'\(', '\)'는 괄호를 의미한다.
'.+?'는 1문자 이상이라는 의미이다.
93. 문자 수를 세어 히스토그램으로 표시해보자
survey["length"] = survey["comment"].str.len()
survey.head()
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(survey["length"])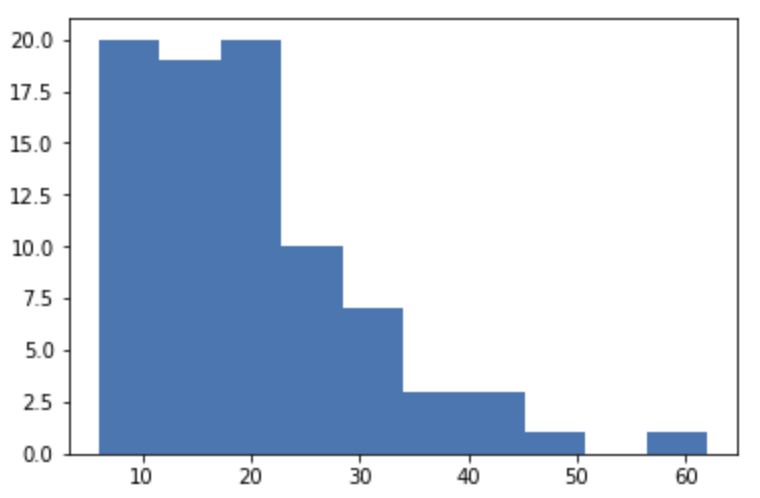
94. 형태소 분석으로 문장을 분해해보자
문장의 특징 파악 : 어떤 단어가 포함돼 있는지를 이해해야 한다.
형태소 분석 : 문장을 단어로 분할하는 기술
라이브러리 : konlpy
이 library는 문장의 단어들을 품사로 분해할 수 있다.
from konlpy.tag import Twitter
twt = Twitter()
text = "형태소분석으로 문장을 분해해보자"
tagging = twt.pos(text)
tagging
1행에서 konlpy 라이브러리를 불러오고, 2행에서 초기화합니다. 3행에선 형태소 분석을 할 문장을 지정하여 pos를 이용해서 형태소 분석을 한다.
출력 결과를 보면 단어 및 품사가 리스트 형태로 표시된다. 그러면 단어만 리스트 형 변수에 저장된다.
words = twt.pos(text)
words_arr = []
for i in words:
if i == 'EOS': continue
word_tmp = i[0]
words_arr.append(word_tmp)
words_arr
1행 pos를 사용해 변수에 저장한다.
0번째 데이터 : 단어
1번째 데이터 : 품사 정보
95. 형태소 분석으로 문장에서 '동사', '명사'를 추출해 보자
여기선 동사와 명사만 추출해 보자. 기본적으로 테크닉 94를 기준으로 확장해가겠다.
text = "형태소분석으로 문장을 분해해보자"
words_arr = []
parts = ["Noun", "Verb"]
words = twt.pos(text)
words_arr = []
for i in words:
if i == 'EOS' or i == '': continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
words_arr.append(word_tmp)
words_arr94와의 차이점은 품사가 동사,명사가 아닌 단어는 word_arr에 저장되지 않느다는 것이다.
실행 결과를 보면 앞에서와는 달리 다섯 단어만 추출된 것을 알 수 있다.
이것으로 단어의 분할뿐만 아니라 특정 단어만 추출하는 것도 할 수 있게 되었다.
96. 형태소 분석으로 자주 나오는 명사를 확인해 보자
all_words = []
parts = ["Noun"]
for n in range(len(survey)):
text = survey["comment"].iloc[n]
words = twt.pos(text)
words_arr = []
for i in words:
if i == "EOS" or i == "": continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
words_arr.append(word_tmp)
all_words.extend(words_arr)
print(all_words)코드 내용
survey의 comment 칼럼을 for 문으로 반복하면서 테크닉 95와 같이 형태소 분석을 실행해서 words_arr에 일시적으로 저장하고, 이것을 extend로 리스트끼리 결합해서 all_words에 저장한다.
실행 시 명사만 추출된다.
단어별로 빈도수를 알기 위해선 데이터 프레임에 저장하고 집계해서 자주 나오는 단어 5개를 표시하자.
all_words_df = pd.DataFrame({"words":all_words, "count":len(all_words)*[1]})
all_words_df = all_words_df.groupby("words").sum()
all_words_df.sort_values("count",ascending=False).head()
1행에서 단어와 빈도수를 데이터프레임에 저장
count 칼럼을 작성하여 전부 1을 대입한다.
2행에서는 단어마다 count를 계산하고, 3행에서는 내림차순으로 처음 5행을 표시한다.
여기서는 더, 수, 좀을 노이즈로 생각하여 이는 포함되는 것이 언어 처리의 특징이다.
이를 제거하자.
97. 관계없는 단어를 제거해보자.
stop_words = ["더","수","좀"]
all_words = []
parts = ["Noun"]
for n in range(len(survey)):
text = survey["comment"].iloc[n]
words = twt.pos(text)
words_arr = []
for i in words:
if i == "EOS" or i == "": continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
if word_tmp in stop_words:continue
words_arr.append(word_tmp)
all_words.extend(words_arr)
print(all_words)96과의 차이점은 stop_words라는 변수를 정의하고, 명사가 만약 stop_words인 경우에는 words_arr에 추가하지 않게 한다. 제외 키워드는 시행착오를 거쳐 늘어날 가능성이 있기에 리스트형으로 유지한다.
이때 엑셀과 같은 파일에 저장하고 꺼내쓰는 방법을 추천한다.
all_words_df = pd.DataFrame({"words":all_words, "count":len(all_words)*[1]})
all_words_df = all_words_df.groupby("words").sum()
all_words_df.sort_values("count",ascending=False).head()
코드를 실행한 결과, 이전과 달리 '더', '좀', '수'가 없어지고, 새로운 단어가 생겼다.
98. 고객만족도와 자주 나오는 단어의 관계를 살펴보자.
여기선 comment 칼럼을 불러와서 형태소 분석을 한 단어와 고객만족도를 연결해야 한다.
형태소 분석을 하면서 고객만족도를 satisfaction이라는 변수에 저장한다.
stop_words = ["더","수","좀"]
parts = ["Noun"]
all_words = []
satisfaction = []
for n in range(len(survey)):
text = survey["comment"].iloc[n]
words = twt.pos(text)
words_arr = []
for i in words:
if i == "EOS" or i == "": continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
if word_tmp in stop_words:continue
words_arr.append(word_tmp)
satisfaction.append(survey["satisfaction"].iloc[n])
all_words.extend(words_arr)
all_words_df = pd.DataFrame({"words":all_words, "satisfaction":satisfaction, "count":len(all_words)*[1]})
all_words_df.head()words_arr에 단어를 추가하는 words_arr.append(word_tmp) 아래에 satisfaction에 만족도를 추가하는 처리가 추가된 것이다. 마지막에 데이터프레임으로 저장하면 단어와 고객만족도가 연결된다.
해당 단어의 comment가 만족도면 1을 준다.
words마다 집계하자. satisfaction은 평균값(mean), count는 합계(sum)를 계산한다.
words_satisfaction = all_words_df.groupby("words").mean()["satisfaction"]
words_count = all_words_df.groupby("words").sum()["count"]
words_df = pd.concat([words_satisfaction, words_count], axis=1)
words_df.head()mean, sum으로 계산하고, 각 계산 결과를 결합한다.
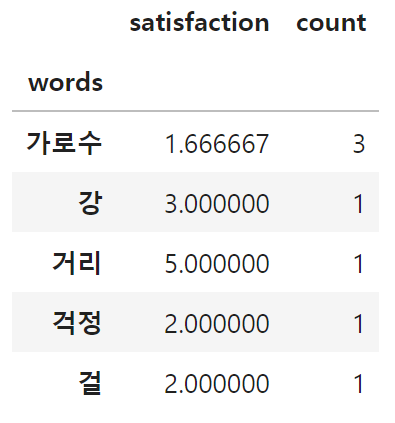
Satisfaction과 count는 groupby를 이용해 각각 mean(), sum()으로 계산하고, 각 계산 결과를 결합한다.
가로수 외에는 모두가 count 1, 이는 1번 밖에 나오지 않은 단어이다.
1번밖에 나오지 않은 단어는 소수이므로, count가 3이상인 데이터만 뽑아서 고객만족도를 내림차순 및 오름차순으로 5개씩 나열해보자.
words_df = words_df.loc[words_df["count"]>=3]
words_df.sort_values("satisfaction", ascending=False).head()
words_df.sort_values("satisfaction").head()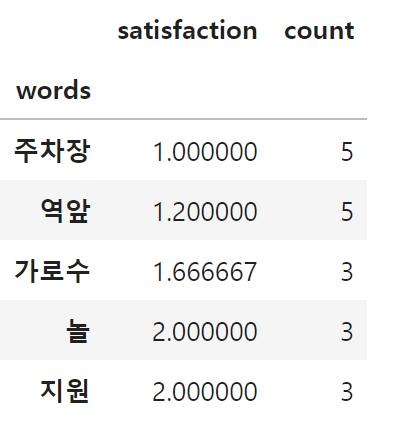
99, 의견을 특징으로 표현해보자
여기서 생각한 것은 어떤 단어가 포함되는 지를 특징으로 정의했다.
parts = ["Noun"]
all_words_df = pd.DataFrame()
satisfaction = []
for n in range(len(survey)):
text = survey["comment"].iloc[n]
words = twt.pos(text)
words_df = pd.DataFrame()
for i in words:
if i == "EOS" or i == "": continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
words_df[word_tmp] = [1]
all_words_df = pd.concat([all_words_df, words_df] ,ignore_index=True)
all_words_df.head()
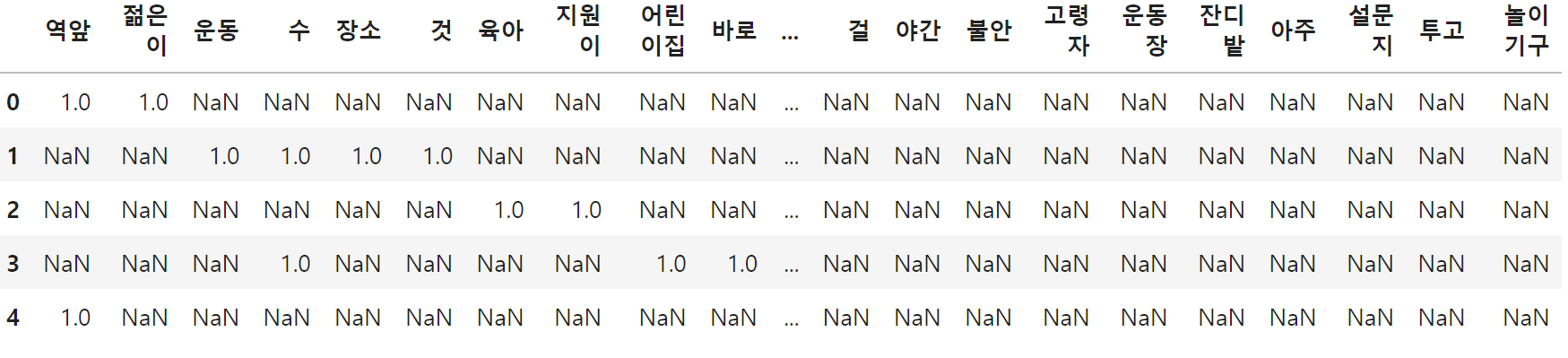
all_words라는 리스트에 저장해왔다.
여기는 all_words_df라는 데이터 프레임을 이용한다.
words_df[word_tmp]=[1]로 단어가 포함돼 있다면 숫자 1을 대입한다.
이것을 모든 의견마다 진행하고 concat으로 결합합니다.
이렇게 하면 의견에 포함된 단어에는 1이, 그 외에는 결측치가 대입됩니다. 실제로 1행 데이터에는 '역앞' 열에 1이 있는 것을 알 수 있다. 다음으로 결측치 0을 대입하자.
all_words_df = all_words_df.fillna(0)
all_words_df.head()
100. 비슷한 설문지를 찾아보자
print(survey["comment"].iloc[2])
target_text = all_words_df.iloc[2]
print(target_text)
'육아 지원이 좋다'라는 의견을 타깃으로 하고,
all_words_df의 인덱스번호가 2인 데이터를 가져온다.
1/0으로 표시
유사도 검사를 실시한다.
문서의 유사도를 지표로 하는 대표적인 수법인 코사인 유사도이다.
import numpy as np
cos_sim = []
for i in range(len(all_words_df)):
cos_text = all_words_df.iloc[i]
cos = np.dot(target_text, cos_text) / (np.linalg.norm(target_text) * np.linalg.norm(cos_text))
cos_sim.append(cos)
all_words_df["cos_sim"] = cos_sim
all_words_df.sort_values("cos_sim",ascending=False).head()
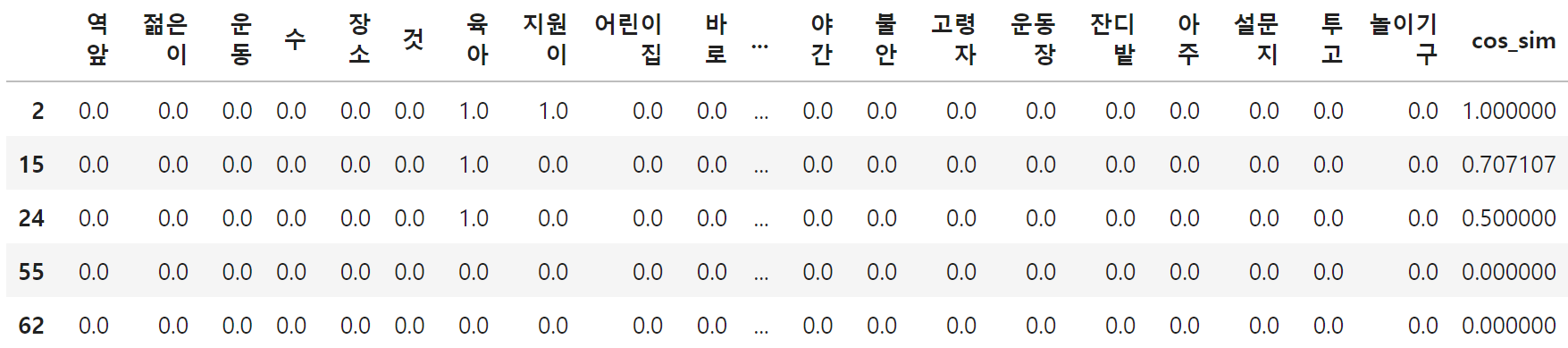
1행 numpy import함.
for 문에서는 전체 의견에 대해 타깃 의견인 ~~와 코사인 유사도를 계산하고, cos_sim이라는 변수에 저장한다.
이를 높은 순으로 표시한다.
index2는 자기 자신이다.
print(survey["comment"].iloc[2])
print(survey["comment"].iloc[15])
print(survey["comment"].iloc[24])

유사도 높은 것을 추출했다.